



专注仓储领域 服务三大群体
-

生产制造
成品,物料,辅材多仓库类型,对接生产系统/MES
-

批发零售
商贸批发:B2B批发模式,对接主流ERP
连锁零售:连锁企业配货仓,对接收银POS
电商零售:自有平台/三方平台,对接OMS
-

三方仓储/3PL
统仓统配业务,云仓业务,综保区保税仓业务等
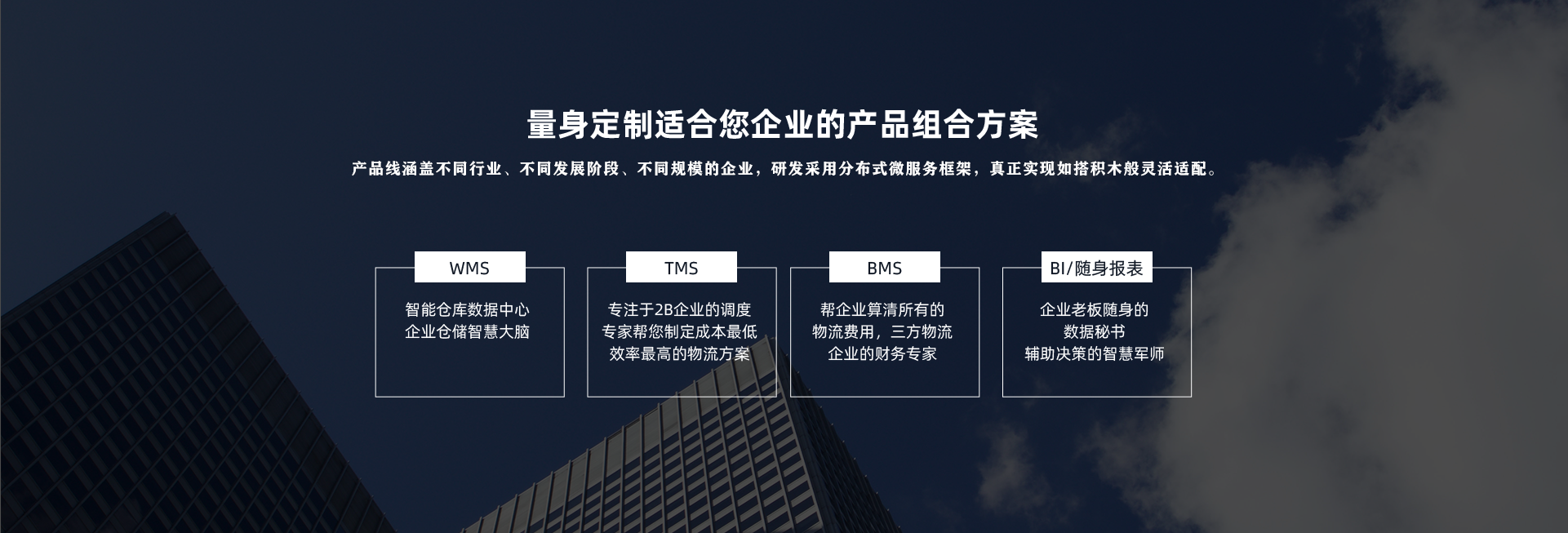
产品能力全景图 定制属于您的产品解决方案
按需购买 只为您所需要的东西付费



仓储物流改善立竿见影 助力企业持续提质降本增效
-
 库存准确率提高至 99%十
库存准确率提高至 99%十库存高效盘点,仓库高度透明,信息实时查看,准确率大大提升。库存安全预警,大大降低库存风险有效保证生产
-
 仓库面积利用率提升 30%十
仓库面积利用率提升 30%十仓库“向上”发展,空间合理规划,各类容器精准细分,人员、设备充分利用,有效减少仓库资源浪费,提高仓库利用率。
-
 仓库生产人效提升 25%十
仓库生产人效提升 25%十仓库布局合理化,系统指引作业,不再依赖老员工仓库考核合理化,人员流动少。
-
 仓库作业效率提升 45%十
仓库作业效率提升 45%十消息及时推送,任务智能分配,整体流程优化,部门高效协同,收货入库、库内管理、拣配出货、智能补货、高效盘点等管理,效率大大提升。
-
 库发货准确率提升 33%十
库发货准确率提升 33%十分拣流程优化、无纸化出库管理、打包发货流程优化、快递面单关联系统订单、过期品出库拦截、错配发货大大减少、客诉减少。
-
 仓库管理成本减少 40%十
仓库管理成本减少 40%十库位设计合理、产品效期批号强制管理、临期品过期品预警显示、拣配货路径优化、货品按ABC排库位,业务分工清晰明确、业务协作顺畅高效等。






您身边的成功转型故事


某工业品案例
***立足西安,专注于以西安为中心300公里范围内次零售终端(五金
门店)的
一站式订货服务,公司拥有60000㎡标准化多楼层仓库,经营
30000+种五金产品。使用天工WMS之前,仓库100余人完全打印发货单
凭靠人的经验去仓库取货,但是传统的模式拣货效率低,准确率低,成本
高,过度依赖于人,
严重制约公司的发展,**2020年牵手天工WMS,经
过1个月的改造,取得了惊人的效果。

10000平

SKU数量
3000种

行业
快销品

购买软件
WMS

企业新闻更多动态+


天工WMS仓储管理系统----入库场景你了解多少
WMS(仓储管理系统)的入库场景是仓储管理的首要环节,直接影响后续作业效率和准确性。将传统依赖人工清点、手动录入的入库流程转变为数字化、智能化的高效作业模式,成为企业仓储管理的重要支撑。
常见问题更多+
-
 天工WMS主要是做什么业务的?
天工WMS主要是做什么业务的?天工WMS聚焦于批发零售、3PL、生产制造群体,为其提供一体化智能仓库升级方案。一体化智能仓库解决方案包含仓储规划服务,物流软件(wms,tms,bms,)开发,物流设备集成,物流sop培训等服务/科技产品。可与上下游系统如ERP,TMS及其他三方系统进行数据交互,形成供应链信息化闭环,同时可集成扫码枪,AGV,输送线,智能分拣。
-
天工WMS的一体化解决方案包含什么?
一、仓储规划(新仓如何选,搬仓怎么快,货物怎么摆,拣货路径如何设置等);二、软件开发(WMS/TMS/BMS/BI等);三、物流设备的集成(扫码枪,AGV,输送线,智能分拣,打包机,自动提单机等);四、物流SOP培训。
-
天工WMS的优势是什么?
提出“可搭配,一体化,敢对赌,错必赔”的十二字方针,承诺真落地,仓储升级零风险。可搭配:搭配企业现有erp使用,也可以打包主流erp/mes等整体输出,给企业仓储一体化升级方案;一体化:输出软/硬件一体化仓储方案,多套系统(ERP/WMS/MES等)一体化交付方案;敢对赌:敢保证真落地,达到实施上线效果再付软件费用;错必赔:由于我方原因造成的仓储损失,敢于赔付损失。
联系我们
 400-963-9559
400-963-9559
 上海市青浦区练塘镇章练塘路588弄15号1幢2层
上海市青浦区练塘镇章练塘路588弄15号1幢2层